字符串的匹配算法(单模式串)
KMP 算法真的是…看了忘,忘了看…每次看时都要从盘古开天辟地开始看…从大一看到现在,真·从小看到大!
本文题目难度标识:🟩简单,🟨中等,🟥困难。
给你两个字符串 haystack 和 needle ,请你在 haystack 字符串中找出 needle 字符串的第一个匹配项的下标(下标从 0 开始)。如果 needle 不是 haystack 的一部分,则返回 -1 。
模式匹配指的是求子串(模式串)在主串中的位置。常见的字符串匹配算法包括暴力匹配、Knuth-Morris-Pratt 算法、Boyer-Moore 算法、Sunday 算法等。
下文中,有时候将题目中的主串 haystack 称为 S,模式串 needle 称为 T。
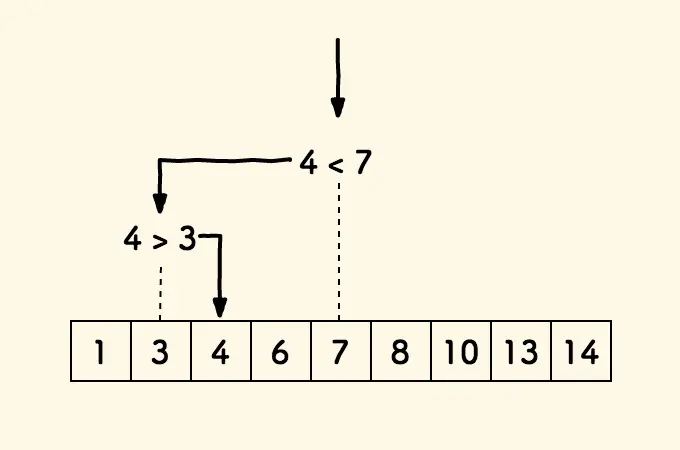
暴力算法(Brute Force, BF)

每次匹配失败,T 串向前走。直到匹配成功或返回 -1。
我们发现,指向 S 和 T 串的指针,在出现失配时需要进行回溯。
1 | public int strStr(String haystack, String needle) { |
时间复杂度(最坏):,其中 n 是字符串 haystack 的长度,m 是字符串 needle 的长度。最坏情况下我们需要将字符串 needle 与字符串 haystack 的所有长度为 m 的子串均匹配一次。
空间复杂度:。我们只需要常数的空间保存若干变量。
RK 算法(Rabin-Karp)
RK 算法是 BF 算法的升级版。
具体思路为:长度为 m 的主串有 n-m+1 个长度为 m 的子串,通过哈希算法对主串中的 n-m+1 个子串分别求哈希值,然后与模式串的哈希值进行比较。
- 如果子串的哈希值与模式串的哈希值不相等,那对应的子串和模式串肯定也是不匹配的,就不需要比对子串和模式串本身。
- 如果某个子串的哈希值等于模式串的哈希值,再进一步对比一下子串和模式串本身,判断是否真的匹配。
对于使用哈希算法计算 n-m+1 个长度为 m 的子串的哈希值的过程,我们要控制其时间复杂度在 ,之内。这样的哈希算法有一个特点,在主串中,相邻两个子串哈希值的计算公式有一定的关系。
例如,要处理的字符串只包含 a 到 z 这 26 个小写字母,那么我们就用 26 进制来表示一个子串,我们把 a 到 z 这 26 个字符映射到 0 到 25 这 26 个数字:
相邻子串计算方法(下图中子串大小为 m=3):
通过上图,你可以轻松得出前后相邻两个子串哈希值的推导公式。
小技巧,对于 、、 这些数,我们可以事先存值减小时间复杂度。
时间复杂度:。如果存在大量的哈希冲突,时间复杂度会退化为 。
KMP 算法(Knuth-Morris-Pratt)
不正经简记:👁️🎩🎬
Knuth-Morris-Pratt 算法,简称 KMP 算法,由 Donald Knuth、James H. Morris(注意,和 站内文章线索二叉树 的提出者 Joseph M. Morris 不是一个人)和 Vaughan Pratt 三人于 1977 年联合发表。
一些定义:
- 真前缀:除最后一个字符以外,字符串的所有头部子串
- 真后缀:除第一个字符以外,字符串的所有尾部子串
- 部分匹配值(Partial Match):字符串的前缀和后缀的最长相等前后缀长度
上图中:
- 上一串表示 S 串,下一串表示 T 串
- 红色表示失配点
- 蓝色和绿色表示匹配成功的部分
- 蓝色表示前后缀相同的部分
失配后将子串这样移,再进行后续的比较:
我们发现整个过程中主串指针 i 不需要回退。
Knuth-Morris-Pratt 算法的核心为前缀函数,记作 ,其定义如下:对于长度为 L 的字符串 s,其前缀函数 表示 s 的子串 s[0:i] 的最长的相等的真前缀与真后缀的长度。特别地,如果不存在符合条件的前后缀,那么 。
| 字符串 | a | b | a | b | |||
|---|---|---|---|---|---|---|---|
index |
0 | 1 | 2 | 3 | 4 | 5 | 6 |
、next |
0 | 1 | 2 | 3 | |||
由 构成的表项我们也可以称为前缀表 next,含义在于当出现失配时,T 串需要回退的位置。
在子串的某一个字符 t[j] 处匹配失败时,我们需要查找该字符前面的那个子串的最大相等前后缀的长度,即 next[j-1],然后使 j 指针退回到 next[j-1],i 指针不变,继续匹配,不断重复这个操作直到匹配成功或者 j 指针大于等于子串长度。
在理解了前缀表及其作用之后,KMP 算法就可以整体上分为两步:
- 计算前缀表。我们可以一边读入字符串,一边求解当前读入位的前缀函数。
- 根据前缀表移动两个指针进行匹配。
1 | public int strStr(String haystack, String needle) { |
复杂度分析:
- 时间复杂度:,其中 n 是字符串
haystack的长度,m 是字符串needle的长度。我们至多需要遍历两字符串一次。 - 空间复杂度:,其中 m 是字符串
needle的长度。我们只需要保存字符串needle的前缀函数。
Boyer Moore 算法
KMP 算法将前缀匹配的信息用到了极致,而 BM 算法背后的基本思想是通过后缀匹配获得比前缀匹配更多的信息来实现更快的字符跳转。
⭐推荐阅读:字符串匹配 - Boyer–Moore 算法原理和实现 | 春水煎茶 (writings.sh)
Boyer-Moore 的核心概念:坏字符和好后缀。坏字符办法和好后缀办法,可以综合使用,也可以单独使用一种,其中坏字符的办法实现更简单一些。
小结
在一般情况下。普通模式匹配的实际执行时间近似为 ,因此至今仍被采用。KMP 算法仅在主串与子串有很多「部分匹配」时才显得比普通算法快得多,其主要优点是主串不用回溯。
后记
这篇文章写完后,遇到相关题目又忘了!
本文参考
- 2023 王道 《408 数据结构》
- 极客时间 - 王争 - 数据结构与算法之美
- 28. 找出字符串中第一个匹配项的下标题解 - 力扣(LeetCode)
- 字符串——单模匹配算法_字符串单模匹配-CSDN博客
- 图解KMP算法,带你彻底吃透KMP-CSDN博客
- 【⭐推荐】字符串匹配 - KMP 算法原理和实现 | 春水煎茶 (writings.sh)(优质文章,附有大量精美图片)
- 一看就懂的字符串匹配算法 之 RK算法-CSDN博客
- Boyer–Moore 算法 - OI Wiki
 微信
微信 支付宝
支付宝